PET COMPUTAÇÃO
PET COMPUTAÇÃO
Toda investigação é “fundamentada” em dados, mas poucos estudos produzem uma “teoria fundamentada” a partir destes dados. Dentre as diversas metodologias de pesquisa existentes Grounded Theory surgiu em 1967 - através do trabalho The Discovery of Grounded Theory: Strategies for Qualitative Research (Glaser e Strauss) - com o objetivo de preencher o espaço que existe entre a teoria e a pesquisa empírica, visto que existem vários métodos para testar teorias mas não especificamente para o estudo da teoria.
Definição
Grounded Theory is a method for generating theory from data
Justamente por ser um método para gerar uma teoria a partir dos dados Grounded Theory baseia-se em um conjunto de hipóteses conceituais integradas geradas de maneira sistêmica para produzir uma teoria sobre uma área substancial.

Visão Geral
Grounded Theory é baseada no modelo conceito-indicador de comparação constante entre indicadores. Para compreendermos o fluxo de trabalho deste processo, precisamos conhecer alguns conceitos simples descritos a seguir:
- Indicador (ou Incidente): Dados reais, como ações e eventos, capturados através de palavras ou sentenças ditas pelo participante.
- Conceito: São em geral, comportamentos ou fatores que estão alterando comportamentos, gerados e refinados por meio da comparação entre indicadores e este conceito emergente.
- Categorias: Representam um nível mais alto de abstração, uma vez que representam um conjunto de conceitos.
- Memos: Durante todo o processo do Grounded Theory o pesquisador documenta as ideias e relações que embasam os conceitos e categorias que estão sendo criadas.
Processo
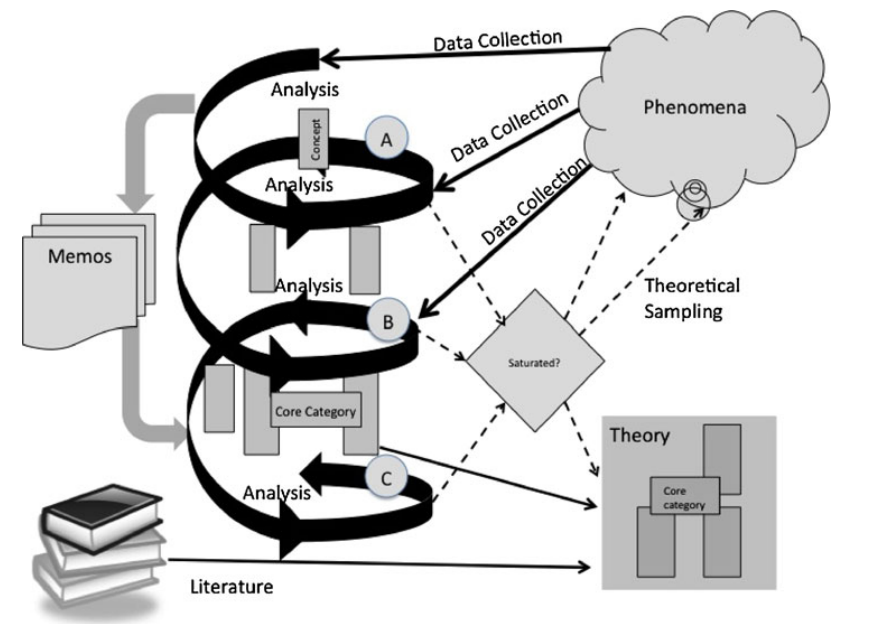
Existem semelhanças com metodologias ágeis de desenvolvimento de software, no sentido que o processo é simples conceitualmente, mas rigoroso e disciplinado na prática. O processo pode ser dividido em três fases principais descritas a seguir e também indicadas na figura abaixo.
- O pesquisador começa a coleta de dados em um fenômeno de interesse e analisa os dados procurando por padrões de incidentes para indicar conceitos que por sua vez são agregadas em categorias.
- As propriedades teóricas da categoria são desenvolvidas através da comparação entre os incidentes nos dados de entrada e os incidentes anteriores na mesma categoria. O processo continua até que as categorias tornem-se "saturadas", isto é, quando a escolha de dados não adiciona qualquer novas propriedades para as categorias existentes.
- Após a saturação, a teoria é comparada com teorias descritas na literatura. A pesquisa bibliográfica é adiada para o final da coleta de dados para evitar forçar teorias preconcebidas sobre a teoria substantiva a ser desenvolvida.
Aplicabilidade
Embora muitos classifiquem Grounded Theory como um método qualitativo, este não é. É um processo geral e como tal, pode ser usado tanto com dados qualitativos ou quantitativos.
No entanto, não é inadequado se a pesquisa visa responder: “A programação em pares é mais efetiva do que programação individual?” mas é adequado caso a pergunta seja: “Como os indivíduos gerenciam o processo de programação em pares?”. Responder esta questão auxiliaria a criação de estratégias para a gerenciar a programação em pares.
Conclusão
Grounded Theory é a geração sistemática da teoria a partir da pesquisa sistemática. Um conjunto de procedimentos de pesquisa rigorosos que levam ao surgimento de categorias conceituais. Estes conceitos / categorias estão relacionados uns aos outros como uma explicação teórica da ação que resolve continuamente a principal preocupação dos participantes em uma área substantiva.
Referências
Por,
Hugo Gabriel Bezerra da Silva - Integrante do PET Computação