 PET COMPUTAÇÃO
PET COMPUTAÇÃO

Vários problemas do cotidiano podem ser tratados matematicamente. Existem na matemática, por exemplo, os problemas de otimização, que consistem em determinar o valor máximo ou mínimo que uma função pode assumir em um dado intervalo. E uma infinidade de situações podem ser descritas como problemas de otimização, como saber a quantidade mínima de moedas para dar um troco, o caminho mais curto entre dois pontos de uma cidade ou o valor máximo de objetos que podem ser colocados em uma mochila sem que estes excedam o peso suportado pela mesma.
Problemas desse tipo podem ser computacionalmente resolvidos utilizando o MÉTODO GULOSO de construção de algoritmos, que visa o alcance de uma solução ótima global a partir da realização das melhores escolhas momentâneas.
Têm-se como características dos Algoritmos Gulosos:
- Em cada iteração escolhem o objeto mais “apetitoso” que veem pela frente;
- Não medem a consequência futura dos seus atos;
- Jamais se arrependem ou voltam atrás, as escolhas em cada iteração são definitivas;
- Têm prova de correção não trivial.
Os Algoritmos Gulosos em geral são rápidos e de fácil implementação, porém em algumas situações a melhor solução não é uma sequencia das melhores escolhas do momento.
Um exemplo de aplicação, é a bastante utilizada CODIFICAÇÃO DE HUFFMAN.
HUFFMAN(C)
n = |C|
Q = C
for i=1 to n-1
alocar um novo nó z
z.esquerda = x = EXTRAIR_MIN(Q)
z.direita = y = EXTRAIR_MIN(Q)
z.freq = x.freq + y.freq
INSERIR(Q, z)
return EXTRAIR_MIN(Q) //retorna a raiz da árvore
A Codificação de Huffman é um algoritmo de compressão de dados que usa a probabilidade de ocorrência dos símbolos no conjunto de dados a ser comprimido para determinar códigos de tamanho variável para cada símbolo, visando atribuir a um símbolo de alta frequência, uma curta sequência de bits. Para isto constrói-se uma árvore binária baseada nas probabilidades de ocorrência de cada símbolo.
Cada folha da árvore representará um símbolo presente no dado e a sua probabilidade de ocorrência. Os nós intermediários representam a soma das probabilidades de seus descendentes, enquanto a raiz representa a soma das probabilidades de todos os símbolos. A cada iteração, são unidos os dois símbolos de menor probabilidade, que são unidos em um nó com a soma destas probabilidades. Este novo nó terá como filhos os elementos que foram somados e passa a ser considerado como um símbolo único. O processo é repetido até que todos os símbolos estejam atrelados à raiz.
A cada aresta da árvore resultante será associado um dígito binário, e o código correspondente de cada símbolo será determinado pelo caminho da raiz até a sua respectiva folha.
Para exemplificar a execução do algoritmo, vamos contrair a string "PERERECA":
Utilizando a codificação ASCII temos a seguinte representação dos caracteres:
Caractere
|
P
|
E
|
R
|
C
|
A
|
Código
|
01010000
|
01000101
|
01010010
|
01000011
|
01000001
|
O que, para representar a palavra, geraria a sequência de bits:
0101000001000101010100100100010101010010010001010100001101000001. Um total de 64 bits.
Utilizando a forma padrão de compressão, onde cada caractere tem um tamanho fixo, a menor codificação que obteríamos seria com 3 bits para cada caractere:
Caractere
|
P
|
E
|
R
|
C
|
A
|
Código
|
000
|
001
|
010
|
011
|
100
|
Gerando a sequência 000001010001010001011100. Um total de 24 bits, 40 a menos que em ASCII.
Para usar o código de Huffman, precisamos montar a árvore. Inicialmente vamos contar o número de ocorrência dos caracteres:
Caractere
|
P
|
E
|
R
|
C
|
A
|
Ocorrência
|
1
|
3
|
2
|
1
|
1
|
Já temos alguns nós na nossa árvore:

Vamos agrupar o dois caracteres menos frequentes em um novo nó:

A cada iteração faremos o mesmo (a melhor solução local: agrupar os dois nós com menor frequência):
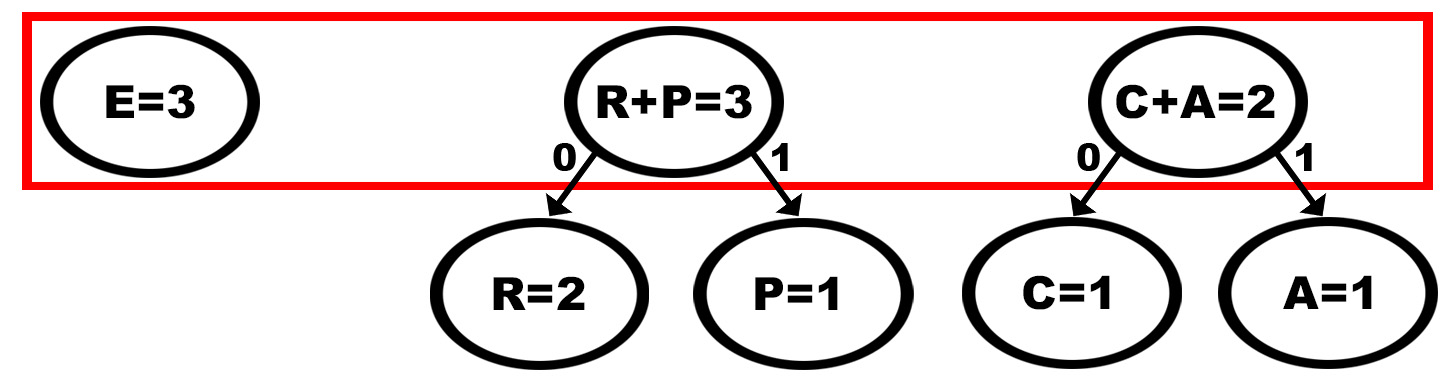
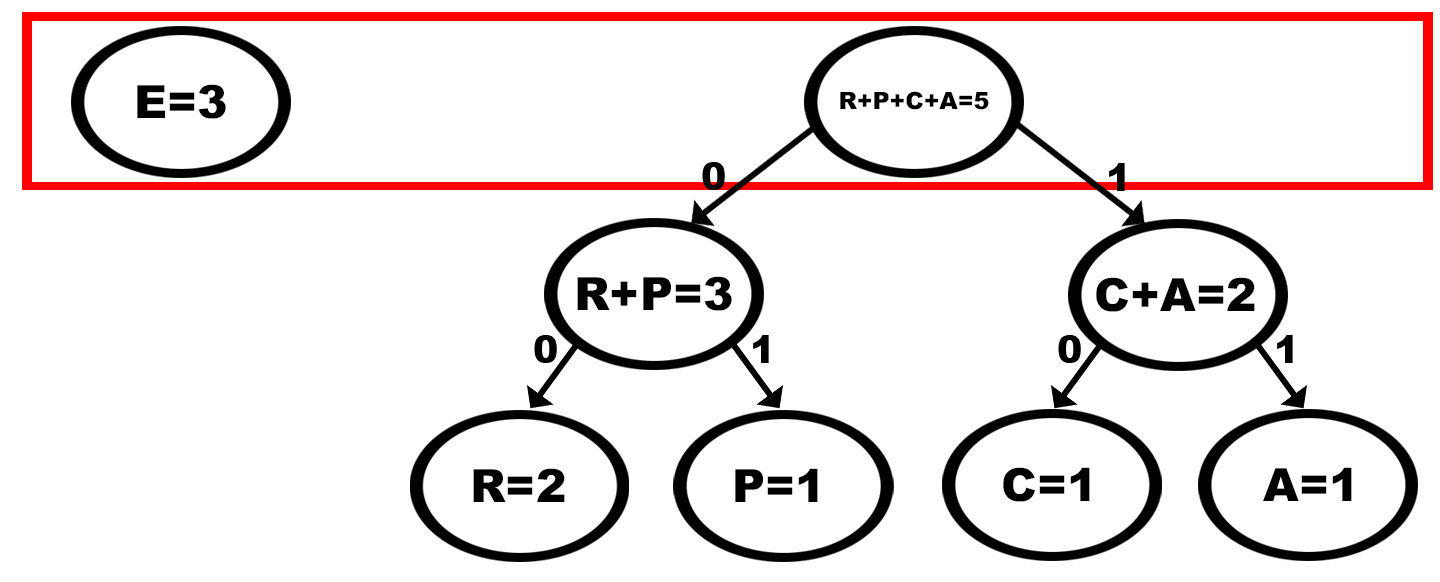
Até, enfim obtermos uma raiz que agrupará todos os caracteres.

O caminho da raiz até a folha que representa o caractere definirá o seu código:
Caractere
|
P
|
E
|
R
|
C
|
A
|
Código
|
101
|
0
|
100
|
110
|
111
|
O que gera a sequência 101010001000110111. Um total de 18 bits, 6 a menos que a compressão padrão e 46 a menos que em ASCII. Para um grande volume de dados a diferença é ainda mais significativa.
Com base em um sequência das melhores respostas do momento, o algoritmo guloso obtêm uma ótima solução global.
Por,
Laybson Plismenn - Integrante do PET Computação


Nenhum comentário :
Postar um comentário